
私は今、Aidemy Premium Plan![]() という、未経験者が3か月で機械学習、ディープラーニング、データ分析、AIアプリ開発まで最先端技術を幅広く学べるオンライン学習サービスで勉強しています。
という、未経験者が3か月で機械学習、ディープラーニング、データ分析、AIアプリ開発まで最先端技術を幅広く学べるオンライン学習サービスで勉強しています。
そして、AIアプリ開発コースにおいて、成果物として画像認識アプリの自主制作に取り組んでいます。
私が製作しているアプリは、『嵐のメンバーでいうと誰似?』というアプリです。顔画像をアップロードすると、嵐のメンバーで最も似ているメンバーを教えてくれるというアプリです。
 と〜げ
と〜げ
完成品は、Herokuで公開しています(http://arashiapp.herokuapp.com/)読み込みに時間かかります。
製作の大きな流れはこんな感じ。
- 学習用の画像の収集
- 嵐メンバーの学習
- Flaskでアプリ作成
今回は、Aidemyの成果物として製作した『嵐のメンバーでいうと誰似?』のアプリ製作の流れを紹介します。
と〜げ
初心者がはじめて作ったものなので、改善すべきところはたくさんあることをご了承ください。私と同じような初心者の参考になればと思います。
※書いているうちに誰に向けて書いているのかわからなくなっていきました。読みづらいでしょうがお我慢を!いつかリライトします。
学習用の画像の収集
画像収集方法
嵐のメンバー(櫻井翔、二宮和也、松本潤、相葉雅紀、大野智)の顔画像を収集します。方法としては以下2つ。
- Bing Image Search APIを使って収集
- 嵐の動画をスクリーンショットして収集
Bing Image Search APIは、Microsoft Azureに登録して使います。詳しくはこちらの記事(関連記事:【Bing Image Search API v7】学習用の画像を収集してみた!)にまとめています。
メンバー1人につき750枚くらいの画像を取得できます。でも、すべての画像が顔画像ではないので、実質350枚くらいです。
Bing Image Search APIだけでは、十分な数ではないので、嵐のYoutube動画からスクリーンショットで350枚ほど取得します。CMのメイキング動画が、画質も良く、正面の顔も多くて、スクリーンショットしやすいのでおすすめです。嵐のような国民的スターは各メンバー単体でCMに出演しているので動画はたくさんありました。
スクリーンショットでも300 ~ 350枚ほど取得しました。
顔検出
学習用の画像を収集しましたが、顔部分以外も写っている画像もあるので、顔部分だけの画像にしてやる必要があります。このように全身の画像を、顔部分の画像にする処理を行います。
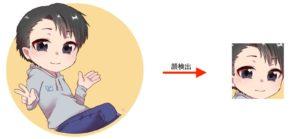
OpenCVというライブラリを使って顔検出をして、顔部分だけの画像を生成します。また、64 x 64にリサイズします。その方法についてはこちらの記事(関連記事:OpenCVのカスケード分類器で顔検出をしてみた!)にまとめました。
こんな感じで顔部分だけの画像にできました。
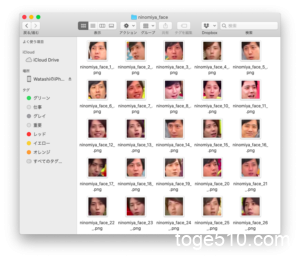
うまく顔検出できなかった画像もあり、結果として、各メンバーに付き、600枚ほどの顔画像となりました。
画像の水増し
学習用の画像は、各メンバーに付き1000枚はほしいと思っていたので、600枚では足りません。なので、画像の左右反転をして水増しを行いました。
import os
import glob
import numpy as np
import matplotlib.pyplot as plt
import cv2
# 左右反転の水増しのみ使用
def scratch_image(img, flip=True, thr=False, filt=False, resize=False, erode=False):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
# flip は画像の左右反転
# thr は閾値処理
# filt はぼかし
# resizeはモザイク
# erode は縮小
# をするorしないを指定している
#
# imgの型はOpenCVのcv2.read()によって読み込まれた画像データの型
#
# 水増しした画像データを配列にまとめて返す
# 画像のサイズを習得、ぼかしに使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
#画像の左右反転のlambda関数を書いてください
lambda x: cv2.flip(x, 1),
#閾値処理のlambda関数を書いてください
lambda x: cv2.threshold(x, 150, 255, cv2.THRESH_TOZERO)[1],
#ぼかしのlambda関数を書いてください
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
#モザイク処理のlambda関数を書いてください
lambda x: cv2.resize(cv2.resize(x,(img_size[1]//5, img_size[0]//5)), (img_size[1], img_size[0])),
#縮小するlambda関数を書いてください
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で水増ししてください
i=0
for func in scratch[methods]:
images = doubling_images(func, images)
return images
# メンバー名
member_name = "ninomiya"
# member_name = "sakurai"
# member_name = "matsumoto"
# member_name = "aiba"
# member_name = "ohno"
# 嵐メンバーの画像フォルダのパス
path ="/content/drive/My Drive/Colab Notebooks/arashi/" + member_name + "_face" # スクリーンショット画像のパス
path_bing = "/content/drive/My Drive/Colab Notebooks/arashi/" + member_name + "_face_bing" # bing apiで取得した画像のパス
# 嵐メンバーの画像フォルダの中の全画像のパスを取得して配列化
img_path_list = glob.glob(path + "/*") + glob.glob(path_bing + "/*")
print(len(img_path_list))
for img_path in img_path_list:
# 画像ファイル名を取得
base_name = os.path.basename(img_path)
# print(base_name)
# 画像ファイル名nameと拡張子extを取得
name,ext = os.path.splitext(base_name)
# print(name + ext)
# 画像ファイルを読み込む
img = cv2.imread(img_path, 1)
scratch_images = scratch_image(img)
# 画像保存用フォルダ作成
if not os.path.exists(member_name + "_scratch_images"):
os.mkdir(member_name + "_scratch_images")
for num, im in enumerate(scratch_images):
# まず保存先のディレクトリ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite(member_name + "_scratch_images/" + name + str(num) + ext ,im)
# print(num)
水増しをした結果、以下の画像数を得ました。とりあえず、1000枚を超えたのでOKとしましょう。
- 櫻井翔 :1198枚
- 二宮和也:1278枚
- 松本潤 :1270枚
- 相葉雅紀:1308枚
- 大野智 :1151枚
水増しについては、こちらのサイト(参考サイト:機械学習のデータセット画像枚数を増やす方法)が参考になりそうです。今度水増しするときはこのサイトの方法を参考にしてみようかと思います。
嵐メンバーの学習
学習モデル作成
では、嵐のメンバー5人の5分類のモデルを作成します。
VGG16モデルを使って転移学習します。VGG以降のモデルは256層の全結合モデルと結合します。modelの16層目までをVGGモデルとします。Flaskのアプリで使うため、モデルの保存もします。
また、学習はGoogle ColaboratoryのGPU環境で行いました。Google Colaboratoryは、Jupyter Notebookをベースとした、Googleの仮想マシン上で動くPython実行環境です。無料で、Googleアカウントさえあれば、すぐにコードを実行することができます。学習に使用する画像はGoogle Driveに保存して、Driveをマウントして読み込みます。
Google Colaboratoryを使用には、これらサイトを参考にしました。参考サイト1:Google Colaboratoryの無料GPU環境を使ってみた、参考サイト2:COLABORATORYとGOOGLE ドライブをマウントする方法
と〜げ
Google ColaboratoryのGPU環境は、めっちゃはやいです!学習には絶対使うべきだと思います。
コードは以下。
import os
import glob
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
# 各メンバー配列格納
member_list = ["sakurai", "ninomiya", "matsumoto", "aiba", "ohno"]
print(member_list)
print(len(member_list))
# 各メンバーの画像ファイルパスを配列で取得する関数
def get_path_member(member):
path_member = glob.glob('./' + member + '_scratch_images/*')
return path_member
# 各メンバーの画像データndarray配列を取得する関数
def get_img_member(member):
path_member = get_path_member(member)
img_member = []
for i in range(len(path_member)):
# 画像の読み取り
img = cv2.imread(path_member[i])
# img_sakuraiに画像データのndarray配列を追加していく
img_member.append(img)
return img_member
# 各メンバーの画像データを合わせる
X = []
y = []
for i in range(len(member_list)):
print(member_list[i] + ":" + str(len(get_img_member(member_list[i]))))
X += get_img_member(member_list[i])
y += [i]*len(get_img_member(member_list[i]))
X = np.array(X)
y = np.array(y)
print(X.shape)
# ランダムに並び替え
rand_index = np.random.permutation(np.arange(len(X)))
# 上記のランダムな順番に並び替え
X = X[rand_index]
y = y[rand_index]
# データの分割(トレインデータが8割)
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# one-hot表現に変換
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデル
input_tensor = Input(shape=(64, 64, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(len(member_list), activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# modelの16層目までがvggのモデル
for layer in model.layers[:15]:
layer.trainable = False
# モデルの読み込み
# model.load_weights('model.h5')
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
history = model.fit(X_train, y_train, batch_size=100, epochs=50, validation_data=(X_test, y_test))
# モデルの保存
# model.save_weights('model.h5');
model.save('model.h5')
# 精度の評価(適切なモデル名に変えて、コメントアウトを外してください)
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# acc, val_accのプロット
plt.plot(history.history['acc'], label='acc', ls='-')
plt.plot(history.history['val_acc'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
学習結果
こちらが、トレインデータ(acc)の正解率、テストデータ(val_acc)の正解率の学習経過です。epochは50です。正解率は以下値くらいに収束しています。
- 訓練データ(acc)の正解率 :0.99
- テストデータ(val_acc)の正解率:0.92
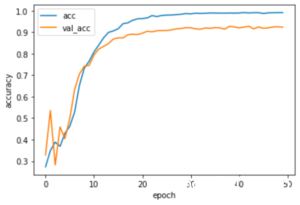
今回は、アプリ作成までの一連の流れを完成させることが目的だったため、テストデータの正解率が80%を越えればOKくらいの気持ちでした。なので、テストデータ(val_acc)の正解率:0.92は思ったり良い値でした。
さらに、正解率を高くするには、トレインデータをより多くしてモデルをより汎化するべきかと思います。画像の水増しをもう少ししてみるといいでしょう。また、VGG以外の転移学習も試してみるとか。
と〜げ
後日、分類に失敗した画像についてなぜ失敗したのかを考えてみました。こちらの記事(【Aidemy成果物】画像分類モデルの分類失敗の原因とは?)で紹介しています。
Flaskでアプリ作成
では、学習結果を使って、Flaskでアプリという形にしていきます。
以下のようなディレクトリ構造でファイルを用意します。
- arashi_flask.py
- haarcascade_frontalface_alt.xml(カスケードファイル)
- model.h5(保存した学習モデル)
- フォルダ:static
- stylesheet.css
- フォルダ:templates
- index.html
まず、arashi_flask.pyのコードは以下。アップロードした画像を顔部分画像にして、学習済みモデルを適用しています。
import os
import cv2
from flask import Flask, request, redirect, url_for, render_template, flash
from werkzeug.utils import secure_filename
from keras.models import Sequential, load_model
from keras.preprocessing import image
import tensorflow as tf
import numpy as np
classes = ["櫻井翔", "二宮和也", "松本潤", "相葉雅紀", "大野智"]
num_classes = len(classes)
image_size = 64
# UPLOAD_FOLDER = "uploads"
UPLOAD_FOLDER = "static"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# 顔を検出して顔部分の画像(64x64)を返す関数
def detect_face(img):
# 画像をグレースケールへ変換
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# カスケードファイルのパス
cascade_path = "haarcascade_frontalface_alt.xml"
# カスケード分類器の特徴量取得
cascade = cv2.CascadeClassifier(cascade_path)
# 顔認識
faces=cascade.detectMultiScale(img, scaleFactor=1.1, minNeighbors=1, minSize=(10,10))
# 顔認識出来なかった場合
if len(faces) == 0:
face = faces
# 顔認識出来た場合
else:
# 顔部分画像を取得
for x,y,w,h in faces:
face = img[y:y+h, x:x+w]
# リサイズ
face = cv2.resize(face, (image_size, image_size))
return face
# 学習済みモデルをロードする
model = load_model('model.h5')
graph = tf.get_default_graph()
@app.route('/', methods=['GET', 'POST'])
def upload_file():
global graph
with graph.as_default():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み
img = cv2.imread(filepath, 1)
# 顔検出して大きさ64x64
img = detect_face(img)
# 顔認識出来なかった場合
if len(img) == 0:
pred_answer = "顔を検出できませんでした。他の画像を送信してください。"
return render_template("index.html",answer=pred_answer)
# 顔認識出来た場合
else:
# 画像の保存
image_path = UPLOAD_FOLDER + "/face_" + file.filename
cv2.imwrite(image_path, img)
img = image.img_to_array(img)
data = np.array([img])
result = model.predict(data)[0]
print(result)
predicted = result.argmax()
pred_answer = classes[predicted] + " 似です"
message_comment = "顔を検出できていない場合は他の画像を送信してください"
return render_template("index.html",answer=pred_answer, img_path=image_path, message=message_comment)
return render_template("index.html",answer="")
if __name__ == "__main__":
app.run()
index.htmlは以下。
stylesheet.cssは以下。
header {
background-color: #76B55B;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
text-align: center;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 30px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 30px 0px 30px 0px;
font-size:24px;
font-weight: bold;
}
.main img {
text-align: center;
}
form {
text-align: center;
margin: 30px 0px 30px 0px;
}
/* footer {
background-color: #F7F7F7;
height: 110px;
}
footer p {
margin: 15px 25px;
} */
見た目はこんな感じです。

デザインなど改良の余地はめちゃくちゃありますが、とりあえず、今回は最低限のレベルということでOKとします。
と〜げ
後日、デザインを修正しました。少しはマシになったかと。。。アプリへ

アプリを使ってみる
嵐メンバー
では、アプリを使ってみましょう。『ファイル選択』から画像を選択して、『submit』します。ここでは、大野君の画像をアップロードすると、「大野智 似です」と表示されます。

model.predictの結果は、以下。左から、[櫻井, 二宮, 松本, 相葉, 大野]。
[7.4453908e-11 4.1521353e-10 6.1165552e-11 1.9962483e-10 1.0000000e+00]
本人なので、大野君の値が1となっていて圧倒的に大野君になっています。
もし、顔検出が出来なかった場合、以下のように表示されます。

似ている芸能人
次に、嵐のメンバーに似ていると言われている芸能人で試してみます。こちらのサイト(【嵐】似ている芸能人のまとめ【ももクロZ】)を参考にしました。
これら芸能人画像をアプリに適用した結果は以下。
二宮和也似の芸能人
- 仲里依紗:櫻井翔似
[櫻井 二宮 松本 相葉 大野] =[0.5107762 0.01505077 0.13981612 0.313571 0.02078576]
- 松山ケンイチ:相葉雅紀似
[櫻井 二宮 松本 相葉 大野]
=[0.00303103 0.00627475 0.2531969 0.73511577 0.00238156]
大野智似の芸能人
- 堂本光一:櫻井翔似
[櫻井 二宮 松本 相葉 大野] =[5.8953154e-01 4.4004153e-04 4.0801790e-01 1.2503696e-03 7.6013181e-04]
相葉雅紀似の芸能人
- 酒井学:相葉雅紀似
[櫻井 二宮 松本 相葉 大野] =[1.7485344e-07 7.9392179e-05 1.8631461e-06 9.9991310e-01 5.4307243e-06]
- 城みちる:相葉雅紀似
[櫻井 二宮 松本 相葉 大野] =[7.0883907e-05 1.2234449e-04 3.6961914e-03 9.9595803e-01 1.5261795e-04]
松本潤似の芸能人
- 水嶋ヒロ:松本潤似
[櫻井 二宮 松本 相葉 大野] =[9.5253235e-05 6.4770742e-05 9.9957150e-01 1.5181383e-04 1.1666931e-04]
-
さかなクン:大野智似
[櫻井 二宮 松本 相葉 大野] =[0.22862583 0.23267555 0.11417166 0.11142252 0.31310448]
全体的には、似ていると言われる芸能人とアプリの結果はあまり一致しませんでした。
しかし、相葉君に似ていると言われる酒井学と城みちるは、アプリの結果と一致します。また、mode.predictの結果もほぼ1という結果でした。相葉君って、嵐のメンバーの中では少し特徴的な顔立ちなので、認識しやすいのかなと思います。
と〜げ
ちなみに、私の顔は、大野智似でした。
[櫻井 二宮 松本 相葉 大野]=[0.00920011 0.05016714 0.00840535 0.07149067 0.8607368 ]
アプリ完成までの道のりとかかった時間
最後に、未経験の私がどのような道のりで、このアプリを完成させたかを簡単に紹介しときます。
Aidemy Premium Plan![]() のAIアプリ開発コースで、python、numpy 、機械学習などのカリキュラムを68時間ほど受講した後に、画像認識アプリの製作に取り掛かりました。
のAIアプリ開発コースで、python、numpy 、機械学習などのカリキュラムを68時間ほど受講した後に、画像認識アプリの製作に取り掛かりました。
アプリ製作にかかった時間は、47.5時間です。日数は10日間です。内訳はこんな感じ。
- 画像収集:27.53時間
- 画像収集:17.86時間
- 顔検出:4.77時間
- 水増し:4.9時間
- 学習:12,97時間
- モデル作成:10.67時間
- Google環境構築:2.3時間
- Flaskアプリ製作:6.97時間
※この他にブログを書くのに7時間ほど使っています。
画像収集に一番時間がかかるとチューターの方に言われていました。結果はその通りで、製作時間の半分以上が、画像収集でした。基本的にこちらのサイト(参考サイト:Kerasでアニメ 「けいおん!」を画像認識させてみた)を参考に製作しました。
と〜げ
未経験の状態から、25日間、学習時間115時間で、一応、アプリを作成できました。めでたし。めでたし。


[…] しかし、前回のブログ(【Aidemy成果物】嵐のメンバーの画像認識アプリを作ってみた!)では、正解率を示しただけで、失敗した画像に関する考察はしていませんでした。 […]