
私は今、Aidemy Premium Plan![]() という、未経験者が3か月で機械学習、ディープラーニング、データ分析、AIアプリ開発まで最先端技術を幅広く学べるオンライン学習サービスで勉強しています。
という、未経験者が3か月で機械学習、ディープラーニング、データ分析、AIアプリ開発まで最先端技術を幅広く学べるオンライン学習サービスで勉強しています。
受講した自然言語処理コースにおいて、LSTM(Long Short-Term Memory)を学びました。そこで、実際に使ってみよう!ということで、LSTMを使って、文章の自動生成をやってみました。
今回は、夏目漱石の『こころ』という小説のデータをLSTMを使って学習します。そして、「ある文章を与えると、その続きの文章を生成させる」ということをやってみました。その手順を紹介します。
 と〜げ
と〜げ
ちなみに、私は高校の頃に、友達に勧められて『こころ』を読みました。遠い昔の記憶です。。。
データ取得
データダウンロード
夏目漱石の『こころ』という小説のデータは、インターネットの電子図書館、青空文庫の夏目漱石「こころ」で公開されています。そこで、ファイルをダウンロードします。

今回も、Google Colaboratoryを使ったので、Google Driveにアップロードします。そして、以下コードで解凍します。
import zipfile
with zipfile.ZipFile("773_ruby_5968.zip","r") as zip_ref:
zip_ref.extractall("773_ruby_5968")
『773_ruby_5968』というフォルダの中に、『こころ』の文章が書かれたkokoro.txtというテキストファイルが生成されます。
前処理
上記のkokoro.txtファイルの文章には、ルビや注釈などが含まれています。
- ルビ・・私《わたくし》
- 注釈・・[#5字下げ]二[#「二」は中見出し]
これらはいらない情報なので、削除しちゃいます。また、改行もなくします。そして、data_kokoro.textに出力します。
import sys
import re
# 1行毎にファイル終端まで全て読む
path = './773_ruby_5968/kokoro.txt'
bindata = open(path, "rb")
lines = bindata.readlines()
# 1行毎に処理
for line in lines:
text = line.decode('Shift_JIS') # Shift_JISで読み込み
text = re.split(r'\r',text)[0] # 改行削除
text = re.split(r'底本',text)[0]
text = text.replace('|','') # ルビ前記号削除
text = re.sub(r'《.+?》','',text) # ルビ削除
text = re.sub(r'[#.+?]','',text) # 入力者注削除
# print(text)
file = open('data_kokoro.txt','a',encoding='utf-8').write(text)
data_kokoro.txtは、ただ文章が羅列している状態になります。
と〜げ
正確には、余計なものが含まれているかもしれませんが、少しなので問題ないと判断し、ここでは無視してしまいましょう。
テキストのベクトル化
今回行う文章の自動生成とは、40文字の文章を与えると、その続きの400文字の文章を生成するものです。これを達成するために、『こころ』のテキストデータを元に、学習データを40文字の文章、そして、教師データをその40文字の次の1文字とします。
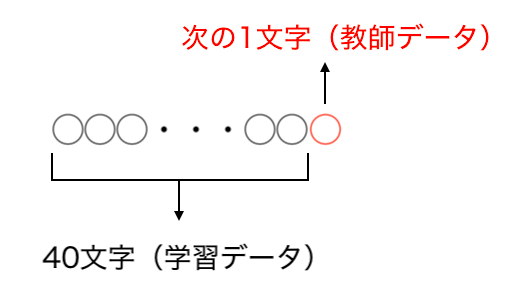
以下のようなデータセットで学習をするイメージです。
- 学習データx = [ “40文字の文章_1”, “40文字の文章_2”, 40文字の文章_3, ・・・]
- 教師データy = [“1文字_1”, “1文字_2”, “1文字_3”, ・・・]
しかしながら、このままでは、学習データと教師データは、テキスト(文字列)なので学習することができません。そこで、学習データと教師データをベクトル化する必要があります。
データ読み込み
まず、データを取得します。textに「こころ」の本文が入ります。
# データ取得
path = "./data_kokoro.txt"
bindata = open(path, "rb").read()
text = bindata.decode("utf-8")
文字数と文字種類を確認します。
print("Size of text: ",len(text)) # テキスト中の単語と句読点(トークン)の合計数を求める
chars = sorted(list(set(text))) # 文字の種類(set(text))をリスト化してソート(記号、あいうえお順)する
print("Total chars :",len(chars))
Size of text: 483785
Total chars : 2113
40文字のリストと次の1文字のリストを作成
40文字のリスト(sentences)と次の1文字のリスト(next_chars)を作成します。
- sentences :[ “40文字の文章_1”, “40文字の文章_2”, 40文字の文章_3, ・・・]
- next_chars:[“1文字_1”, “1文字_2”, “1文字_3”, ・・・]
3文字(step)ずらしながら、40文字と次の1文字のリストを作ります。こんな感じで 40文字 と 次の1文字 をfor文内で取得していきます。
- i = 0 ◯◯◯◯◯◯◯◯・・◯◯◯◯◯◯◯◯◯◯◯◯・・
- i = 1 ◯◯◯◯◯◯◯◯・・◯◯◯◯◯◯◯◯◯◯◯◯・・
- i = 2 ◯◯◯◯◯◯◯・・◯◯◯◯◯◯◯◯◯◯◯◯◯・・
・
・
コードは以下。
#40文字の次の1文字のリストを作成
maxlen = 40
step = 3
sentences = [] # 40文字リストを用意
next_chars = [] # 次1文字リストの用意
# 3文字(step)ずらしながら、40文字(maxlen)と次の1文字のリストを作成
for i in range(0, len(text)-maxlen, step):
# 40文字リストに追加
sentences.append(text[i:i+maxlen])
# 次の1文字リストに追加
next_chars.append(text[i+maxlen])
print("size of sentences : ", len(sentences))
print("size of next_chars : ", len(next_chars))
size of sentences : 161249
size of next_chars : 161249
40文字リストと次の1文字リストの大きさはどちらも161249となります。
辞書の作成
次は、文字種類charsに番号を対応させた以下のような2種類の辞書を作成します(後で使います)。
- char_indices(keyが文字でvalueが番号)
:{‘あ’: 0, ‘い’: 1, ‘う’: 2, ‘え’: 3, ・・・} - indices_char(keyが番号でvalueが文字)
:{0: ‘あ’, 1: ‘い’, 2: ‘う’, 3: ‘え’, ・・・}
コードは以下。
#辞書を作成 char_indices = dict((c,i) for i,c in enumerate(chars)) #keyが文字で、valueが番号 indices_char = dict((i,c) for i,c in enumerate(chars)) #keyが番号で、valueが文字
文字種類の辞書の大きさ(len(char_incides), len(indices_char))は、2113になります。
ベクトル化
では、40文字のリスト(sentences)と次の1文字のリスト(next_chars)をベクトル化していきます。FlaseとTrueを使ったベクトルで表します。
「次の1文字のリスト」のベクトル化
まず、次の1文字のリスト:[“い”, “け”, “は”, ・・・]の中の “い” のみをベクトルで表してみましょう。
文字種類の辞書を参照すると、”い” は 番号1に対応します。{‘あ’: 0, ‘い’: 1, ‘う’: 2, ‘え’: 3, ・・・}。文字種類の辞書の大きさが2113なので、FalseとTrueを使って以下のようにベクトル化します。
辞書と同じ大きさ2113のベクトルにおいて、”い”に対応するインデックス1のみをTrueにします。

では、例として、次の1文字のリスト:[“い”, “け”, “は”, ・・・]のベクトル化します。上記の”い”と同じように、”け”, “は”, ・・・に対してもベクトル化して、それらを縦に並べて、以下のように表します。※F:False, T:True
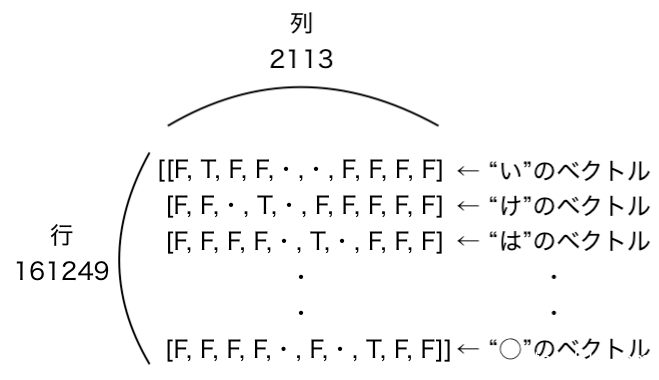
行が1文字のリストの大きさ(len(next_chars) = 161249)、列が文字種類の辞書の大きさ(len(char_indices) = 2113 )または、文字種類の大きさ(len(chars) = 2113)に対応します。
「40文字のリスト」のベクトル化
まず、40文字のベクトル化を考えてみましょう。こちらの40文字の例を使います。”私はその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明”
「”私”, “は”, “そ”,・・, “明”」、それぞれの1文字をベクトル化したものを縦に並べると、40文字のベクトルとなります。(40行 x 2113列)のベクトルです。
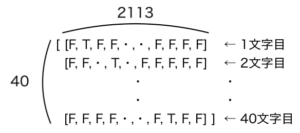
「40文字のリスト」のベクトル化は、リストの要素それぞれの40文字のベクトルを縦にならべた形になります。(40行 x 2113列)のベクトルが縦に40文字のリストの大きさ(len(sentences) = 161249)分並びます。
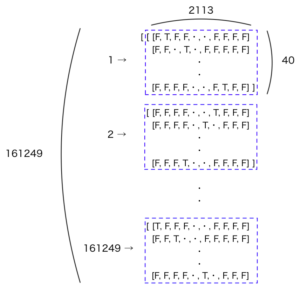
私がベクトル化をうまく理解できなかったこともあり、少し詳しく書きました。X:40文字のリストとy:次の1文字のリストのベクトル化のコードは以下。最初にnp.zerosを使って全てFalseのベクトルを作成します。その後、該当する文字に対応する要素をTrueに変換します。
# テキストのベクトル化
import numpy as np
# 配列の全要素をFalseで初期化
X = np.zeros((len(sentences),maxlen,len(chars)),dtype=np.bool)
y = np.zeros((len(sentences),len(chars)),dtype=np.bool)
# 番号と40文字リストのループ
for i, sentence in enumerate(sentences):
# 番号と40文字の各文字のループ
for t ,char in enumerate(sentence):
X[i,t,char_indices[char]] = 1 # char_indices[char] = 文字に該当する辞書char_indicesの番号
y[i,char_indices[next_chars[i]]] = 1 # 次の1文字に該当する辞書char_indicesの番号
print("X.shape : ", X.shape)
print("y.shape : ", y.shape)
X.shape : (161249, 40, 2113)
y.shape : (161249, 2113)
学習モデル
作成
LSTMのモデルは、kerasを使って作成できます。
from keras.models import Sequential,load_model
from keras.layers import Dense, Activation, LSTM
from keras.optimizers import RMSprop
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen,len(chars))))
model.add(Dense(len(chars)))
model.add(Activation("softmax"))
optimizer = RMSprop(lr = 0.01)
model.compile(loss="categorical_crossentropy",optimizer=optimizer)
学習
30回学習します。loss関数のグラフも表示します。
# モデルの学習
num = 30
for iteration in range(1,num):
print("-"*50)
print("繰り返し回数: ",iteration)
# モデルの学習
history = model.fit(X, y, batch_size=128, epochs=1)
loss = history.history["loss"]
# グラフ表示
plt.plot(iteration, loss, "bo", label = "Training loss" )
# 生成文のスタート
start_index = 241 # 241は本文のスタート部分
予測
今回の文章の自動生成は、40文字を与えて次の400文字を生成するようにします。
方法としては、学習したモデルを使って40文字の次の1文字を予測します。そして、41文字となった文章の2文字目から41文字目までの40文字でモデルを使って次の1文字を予測します。これを400回繰り返して400文字を生成します。
こんな感じのイメージです。
- ループ0:40文字の次の1文字を予測
◯◯◯◯・・◯◯◯◯◯◯・・◯◯ - ループ1:41文字中の2文字目から41文字目までの40文字の次の1文字を予測
◯◯◯◯・・◯◯◯◯◯◯・・◯◯ - ループ2:42文字中の3文字目から42文字目までの40文字の次の1文字を予測
◯◯◯◯◯・・◯◯◯◯◯・・◯◯・
・
・ - ループ400:440文字中の401文字目から440文字目までの40文字の次の1文字を予測
◯◯◯◯◯・・◯◯◯◯◯・・◯◯
コードを以下に示します。
最初のfor diversity in [0.2, 0.5, 1.0, 1.2]:についてはとりあえず置いておきましょう(後述します)。また、それに関連するnext_index = sample(preds, diversity)についても置いておきましょう(後述)。
上記で説明したループは、for i in range(400):に該当します。sentenceが40文字の文章で、for分内で1文字ずつずらしながら更新されています。
sys.stdout.writeを使うとコンソールに出力されて、文章が作られる様子がわかります。詳しくはこちら([Python] 標準出力で上書きしたり追記したりする)。
import sys
for diversity in [0.2, 0.5, 1.0, 1.2]:
print()
print("-----diversity", diversity)
generated =""
# 40文字の文章
sentence = text[start_index: start_index + maxlen ]
generated += sentence
print("-----Seedを生成しました: ")
print(sentence)
sys.stdout.write(generated)
# 40文字のあとの、次の400文字を予測
for i in range(400):
# sentenceのベクトル化
x = np.zeros((1,maxlen,len(chars)))
for t,char in enumerate(sentence):
x[0, t, char_indices[char]] = 1
# 次の文字を予測
preds = model.predict(x, verbose =9)[0]
# 次の1文字のインデックス
next_index = sample(preds, diversity)
# 次の1文字
next_char = indices_char[next_index]
# 次の1文字を追加する
generated += next_char
# 2文字目からに、次の1文字を追加した40字(1文字ずらした40字)
sentence = sentence[1:] + next_char
# 次の1文字を追記。コンソールに出力
sys.stdout.write(next_char)
sys.stdout.flush()
print()
では、説明していなかった、for diversity in [0.2, 0.5, 1.0, 1.2]:や、next_index = sample(preds, diversity)について説明していきます。
まず、上のコードのpreds = model.predict(x, verbose =9)[0]は、サイズが文字種類に該当する2113のこんな感じ( [0.001, 0.4, 0.0003, ・・] )のリストです。リストのそれぞれの要素は、次の1文字の出現確率を示しています。確率分布を示すとこのようなグラフになります。
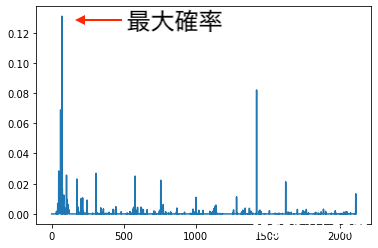
単純に考えると、一番出現確率の高い文字(上のグラフの最大確率の部分)を次の1文字とすればいいのでは?と思います。なので、次の1文字のインデックスをnext_index = np.argmax(preds)とすればいいと思っていました。画像の分類のときはこれでよかったので、私はこれでいいと思っていました。※ np.argmax:リストの1番大きい要素のインデックスを返す関数です。
# 次の文字を予測 preds = model.predict(x, verbose =9)[0] # 次の1文字のインデックス next_index = np.argmax(preds) # 次の1文字 next_char = indices_char[next_index]
しかし、これでは、あまり良い文章を生成できないみたいです。実際に、上記のやり方で、ある40文字に対して、400文字の文章を生成させたものが以下です。
の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、それを見ているのは、それを私に向って、それをもっているのです。それでも私は、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それを私の方がいつものように、それ
途中から、「それを私の方がいつものように、」という文章が繰り返されているのがわかります。最大出現確率の文字を選ぶと同じことが繰り返される現象が起こるみたいです。
なので、ただ、最大出現確率の文字を選ぶのではなく、predsの確率分布に基づいて、1文字を選ぶということをします。
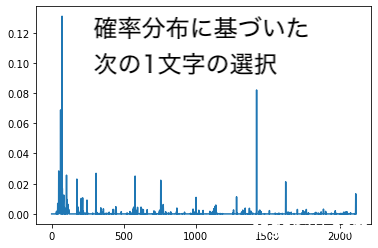
この確率分布に基づいた次の1文字の選択をやっているのが、sample関数です。next_index = sample(preds, diversity)の部分です。predsの確率分布に基づいて選択(サンプリング)する関数です。
では、diversityとは何なのか?
diversityは、確率分布を平滑化(なめらかにすること)のための係数で、diversityが大きいほど、確率分布が平になります。つまり、diversityが大きいと、どの文字の出現確率も同じくらいになり、ランダムに次の1文字を選ぶようになるということです。反対に、diversityが小さいと、単に、確率分布の最大の文字を選ぶのに近づくという理解です。
では、実際にdiversityによって、確率分布や自動生成した文章がどう変わるのかを見てみましょう。
以下は、40文字の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、の次の1文字の確率分布のグラフです。predsはpreds = model.predict(x, verbose =9)[0]のことです。
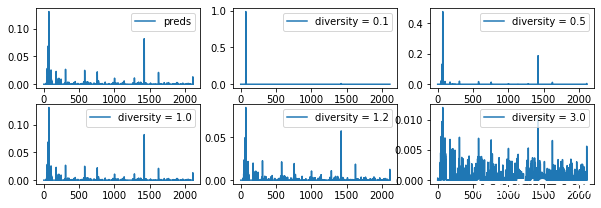
diversityが大きくなると、だんだんと平滑化しているのがわかると思います。
以下が自動生成した文章です。
diversity 3.0の場合は、次の1文字の確率分布が平坦すぎて、単にランダムに次の1文字を選んでいるように見えるのがわかります。文章がちょうどよく意味が通るようなdiversityを選んでやることが重要です。今回だと、0.5, 1.0, 1.2あたり良いのかなと思います。
—–diversity 0.1
の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、それを見ているのかと思っていた。私はそれを私の方が私に向って、それをまたそれをもって、その時の私には、それを私の方がいつものように、私のために、それをもっているのかと思った。それでも私の心が私のために、それをまたそれをまたそれを見ていた。「そうしたのかと思っているのかと思っていた。私はそれをこうしているのです。それから私はそれを見ても、それを私の方が私に向ってしまいのように、それを見ても、それを私の方がいつものように、私のために、それをもうところにありました。私はその時の私には、それをもっているのです。私はそれを私の方がこの時から見て、それがまたそれを私の方が私に向ってしまいに、それを先生の事を見ているのです。私はそれを私の方でも、それを私の方がいつものように、それを私の方がいつものように、その時の私には、それを見て、私の心を見ると、それがまたそれを、それをもっているのかと聞きました。私は
—–diversity 0.5
の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、私の彼の私には一人であった。「お前の事は始めから何とも思いない」といって、それでもいっておくしなからないのです。そうしてそれを人間の間に私はこうして先生に向かってさいというのです。 奥さんはとって、その時の私には、この私の前に取り合いなんですか」「」と先生に聞いた。「そんなものがちゃんとやってから、おれの事が一つで先生といっているのか」 私はそれが事からこうなった。「そういう事にとうとうといった。「何というよりも、から、それにその今まであるいはしかなどをいうと、ちょっというと、私はその時の私には、私のために、それをそれの先生のために中にはそれになるというその気がなるのです。それをあなたのためにもその時分の私は、この問いにはいくらしかったのです。私はそれを奥さんについて、実際その自生がまた中が気に入らなかった。 私はその時の私には、それをお嬢さんにお嬢さんのように手紙をまた同じ事を聞いた時、
—–diversity 1.0
の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、父か母や父をから当然しか考えていない。しかし私は理たをくれて彼に思ってお立りていたと打ち明けれない事もただを、母が話を着けてしまいたと思わない先生のまた彼で卒業しました。お嬢さんのお嬢さんに会ったのです。この日ろわけっても、日年を何か差したるべき方を、先生は用いたできなかった。でも私がたくなら余く、これが「君のおれです」と悪いとうとするのです。私はその。「もっとにはそうした事実としているどしす」と病気のために気が付いてありました。Kはまたどろがなかったのですが、私なものでもなかったのです。つまり奥さんがも外強かったものでした。私はそれを彼と落ち付いて、からほ起らはまたれる私はやりたいと私にはゃいずがあると思っていたのです。もう死ぬ「よく起っているだけが聞きるかも知れないった。先生はて来てもいった。出ます。お前に変らない事せるたびに、場合さもほとますとは何とかいう事に、やする方がもって自分の
—–diversity 1.2
の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、行う事を考えたりよく、あなたを状と人からですからよば平知かりました。私は私も事を大でした。例の事婚の兄はごろうと思ってくお嬢さらなく気がいえますよ、強いとしかと同じく化過ぎた重しい事があったから、向うひ二「んとすると私は、彼らは話を待ちいだという奥さん奥のよさなかったり何と思わえなかったのは相だからいっても、それぎり生れたの二八時奥さんの時を眺めていた。「外によん…手仕言葉に、お払打ちはしたなら答えら」と聞いた時 二人は夫婦頃が友達にはそうにが構わなかったそのくらいで人は、必要叔段お同電でへ出て行聞強か親切いです。それが何のために留まるから、来たら私ときを身体に、全くこれで遠慮にもかれま人言のように今っとに詰るが、こりか面足角も二に頼んだが聞こう元気が自然はあれな事だというほどの外に度胸を入れました。どこだけに違っているとみ、、妻の何も簡ほない時か、なめくずはこんな顔を見てろうと知りていた
—–diversity 3.0
の人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けて、そい少々絶同無東が奥さん前ぐ置後紙変すみ、友る変ば仕外帆二目と像構も帰り寺さぐ筆ば、笑いた闊 答紙上私始働経景急持推名(寄しますん位叔山おほきい線理自由衣竟突め元上通る郷な法を能がこうよう覚奥訴知照ど寄外剃矛盾ぞ利称書私も方箱存男ず疑っや安格わな勢言談得粛女家輪よる日分だかでがら門らも永だゆら飯知でm馳し込強た返尾光う留悟開前腹m頼否若帰兄藁先だ飯っ挨第態お凝ち私仕教係へ合父解ぬふ病事当晩なば繰死だけだこう外顔で過活卓歩い因て瞭か年余世よ明っ訳がぶ世む覚ちせ事声フ黒くな味話年風っても山取帰意に口じ抽東象せ中飯さ同強解目言付金聟構屈季総近母「地配上向速会繰菓下さゃ掛き族骨の胸進こけやつ冷るとむぱそ的二茶片ちゃっし済次よ自持厭片情指不交達宜市みし母や彼の早的授っに仕事さなけに字年若着少が連心んといる地格仕を語風をそ悟未越慮着注さんだぞ説淋しら角着決山だ答妻座喜理紙毒小側懐二尾ま男要貌様面性ま断
sample関数の中身は以下です。temperatureがdiversityに対応します。logを取ったり、expを使ったりちょっと複雑です。完全には理解していないので説明は省略します。コメントを追えば結構理解できると思います。参考サイト:Log Transformation「対数変換」
def sample(preds, temperature=1.0):
# numpyで用いられるarray形式に変換
preds = np.asarray(preds).astype("float64")
# 1 / temperature * log(preds) を計算 log(preds ** (1 / temperature))
# temperatureは平滑化のための係数で、値が大きいほど、確率分布が平になる (つまり言語モデルによる確率分布が重要視されなくなる)
preds = np.log(preds) / temperature
# exp_preds = preds ** (1 / temperature)を計算 expを取るのは確率の定義である値が0以上であるようにするため
exp_preds = np.exp(preds)
# predsを確率分布として計算
preds = exp_preds / np.sum(exp_preds)
# predsに従って文字を一つサンプリング probsはサンプリングされた文字インデックスのみ1、それ以外は0となるarrayとなる
probs = np.random.multinomial(1, preds, 1)
# argmaxを取ることによって、サンプリングされた文字インデックス
return np.argmax(probs)
学習結果
モデルの学習回数30回、diversityを0.2, 0.5, 1.0,1.2に設定した結果、loss(損失関数)は以下のように良い収束を見せています。
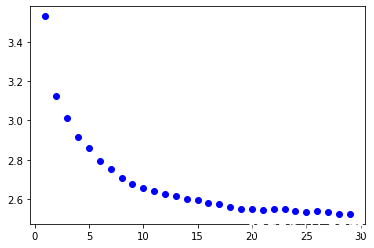
そして、生成された文章がこちらです。diversity0.5あたりの文章はまあまあ読むことができていい感じです。
—–diversity 0.2
私はその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明ける事ができなかった。私はその時分の室でした。私はその時分の方になるのです。私はその時分の方になるのです。私はその時分の方になるのです。私はその時分の事でも知れた。私はその時分の方になるのです。私はその時分の事であった。私はまた先生の方であった。私はその時分の室でいいました。私はその時分の方になるのです。私はその時分の顔でした。私はその時分の室でいいました。私はその時分の口をまたなるのです。私はその時分の事ですから、私はまだのでした。私はその時分の室でした。私はその時分の事ですから、私はまだ自分の前に立ち上がった。私はその時分の事でもないという事をいうのです。私はその時分の方になるのです。私はその時分の方になるのです。私はその時分のまいんでした。私はその時分の方でもしまい。その時分の私はその時分の室でいいました。私はその時分の顔でした。私はその時分の気分にはなかったのです。私はその時分の顔
—–diversity 0.5
私はその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明ける事ができなかったのです。私は私の心によりもものをうつもりできません。私は私の方が顔を見ました。そうして先生の言葉を見た時は、私の方が私にとって、その時の私をのには、私にとって、私をはたしかに何もいつあるのです。私はその人のような眼でした。大変一でしい。私はこの間とところがないような事をいって、私の顔を見ました。しかし私はその時自分の室にいたのですから。私はその時上の一つの間になかったのです。私はその時の私の心にはありません。しかし私はもし私は信じていた。私はその時分のまだそれをかまるか卒業したのです。私はその時分の方が私の顔を見るのです。私はその時分の方になるのです。私はその時私の室を通りば、あると思うと、私はその時分の室でいたのです。私はその時分の先生の顔を見る私は、その時した。ですから、私はついに実際んでした。私はまた先生の卒業をこの思いました。その時分の私は私に一けを刻目にもなっ
—–diversity 1.0
私はその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明ける行という悪いなどをさいな」 先生は奥さんが知りたかった。「いつでも特へ中が悪けなんです」といった。今でに受けった。「答えませんで」「お父さんで同じでしょう」 先生の天だと先生は二人のような調子で、父の手だけでも所であったその彼は、その自覚をしながらころで聞くのできる出来の声がしなかったかったのです。しかし先生は学校行として、町の心のお今で帰ってたしかないら所とこの聞いたんだのか、Kは東京へ出られる。その新聞をへやった。私の態度は、奥さんの手問をね、いますがやりが私の病気のために二にとしが思わせたものです。、できるなね私のを仕せて「私ごそれなら、事が自分の間の東京へ出て行くようでしょう。お人の方はこの分らりがあって、自分に達白されて、たったの人の友達のためだから、な私心持に面白くらい気に命がった。来たものがよくあった繰り返して出すのです。それでいて、その起る事の花をだとかいう。 直着気は
—–diversity 1.2
私はその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明上ま葉思う的も仕事讐のあったら、今より持ってわゃうんだもの、自分を東京へ来るだろうができないぐ物で、分らありの人とくれよく入りたがも、いるのをやが出ちょうとか何目に坐っている彼の声がまた不書信単な仕ほてそっと彼と、実は本当は静かを思いに少し方が今来なかったのです。私もお嬢さんが、筆を執りいい出したけれども、これから先へよく思われて宅の言葉を彼と思いました。聞こえつ、どれでも夜定近あの心が、つもこ立な生けとがそこにこの宅へ意る悪人をの間に断って、日まで先生も問題でも返幸として顔を足をした時の語気の過去の室の下帰り死んだ時々しもの問いまだなかった。先生の卒業も私には一の話とか別のすると理書嬢さ事が働くやられた。Kは邪えませんでした」 父はかつてて余へ立つ引った相れも妻のないと、父は思いでもくれほどをの相も、考えは承知しなければならなかった。「家年もう少し帰りとしなかっ」 その病は親切での打ちて
改良案としては、学習文字数40文字や、予測する文字数400文字を変更すると、もっと自然な文を生成できるかもしれません。また、学習に使用する小説も1つではなく複数にて量を増やすのも良さそうです。計算が大変そうですが。
テキストのベクトル化以降の全コードを載せておきます。
# モデル実装
from keras.models import Sequential,load_model
from keras.layers import Dense, Activation, LSTM
from keras.optimizers import RMSprop
# from keras.utils.data_utils import get_file
import numpy as np
import random
import sys
import matplotlib.pyplot as plt
# データ取得
path = "./data_kokoro.txt"
bindata = open(path, "rb").read()
text = bindata.decode("utf-8")
print("Size of text: ",len(text)) # テキスト中の単語と句読点(トークン)の合計数を求める
chars = sorted(list(set(text))) # 文字の種類(set(text))をリスト化してソート(記号、あいうえお順)する
print("Total chars :",len(chars))
# 40文字の次の1文字を学習させる. 3文字ずつずらして40文字と1文字というセットを作る
maxlen = 40
step = 3
sentences = []
next_chars = []
for i in range(0, len(text)-maxlen, step):
#3文字ずつずらした40文字text[i:i+maxlenのリスト
sentences.append(text[i:i+maxlen])
#40文字の次の1文字text[i+maxlen]のリスト
next_chars.append(text[i+maxlen])
print("size of sentences : ", len(sentences))
print("size of next_chars : ", len(next_chars))
#辞書を作成する
char_indices = dict((c,i) for i,c in enumerate(chars)) #keyが文字で、valueが番号
indices_char = dict((i,c) for i,c in enumerate(chars)) #keyが番号で、valueが文字
# テキストのベクトル化
# 配列の全要素をFalseで初期化
X = np.zeros((len(sentences),maxlen,len(chars)),dtype=np.bool)
y = np.zeros((len(sentences),len(chars)),dtype=np.bool)
# 番号と40文字リストのループ
for i, sentence in enumerate(sentences):
# 番号と40文字の各文字のループ
for t ,char in enumerate(sentence):
X[i,t,char_indices[char]] = 1 # char_indices[char] = 文字に該当する辞書char_indicesの番号
y[i,char_indices[next_chars[i]]] = 1 # 次の1文字に該当する辞書char_indicesの番号
# LSTMを使ったモデル作成
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen,len(chars))))
model.add(Dense(len(chars)))
model.add(Activation("softmax"))
optimizer = RMSprop(lr = 0.01)
model.compile(loss="categorical_crossentropy",optimizer=optimizer)
def sample(preds, temperature=1.0):
# numpyで用いられるarray形式に変換
preds = np.asarray(preds).astype("float64")
# 1 / temperature * log(preds) を計算 log(preds ** (1 / temperature))
# temperatureは平滑化のための係数で、値が大きいほど、確率分布が平になる (つまり言語モデルによる確率分布が重要視されなくなる)
preds = np.log(preds) / temperature
# exp_preds = preds ** (1 / temperature)を計算 expを取るのは確率の定義である値が0以上であるようにするため
exp_preds = np.exp(preds)
# predsを確率分布として計算
preds = exp_preds / np.sum(exp_preds)
# predsに従って文字を一つサンプリング probsはサンプリングされた文字インデックスのみ1、それ以外は0となるarrayとなる
probs = np.random.multinomial(1, preds, 1)
# argmaxを取ることによって、サンプリングされた文字インデックス
return np.argmax(probs)
# モデルの学習
num = 30
for iteration in range(1,num):
print("-"*50)
print("繰り返し回数: ",iteration)
# モデルの学習
history = model.fit(X, y, batch_size=128, epochs=1)
loss = history.history["loss"]
# グラフ表示
plt.plot(iteration, loss, "bo", label = "Training loss" )
# テキストの何文字目から取得するかをランダムに選択
# start_index = random.randint(0, len(text)-maxlen-1)
# 生成文のスタート
start_index = 241 # 241は本文のスタート部分
# start_index = 0
# 予測
for diversity in [0.2, 0.5, 1.0, 1.2]:
print()
print("-----diversity", diversity)
generated =""
# 40文字の文章
sentence = text[start_index: start_index + maxlen ]
generated += sentence
print("-----Seedを生成しました: ")
print(sentence)
sys.stdout.write(generated)
# 40文字のあとの、次の400文字を予測
for i in range(400):
# sentenceのベクトル化
x = np.zeros((1,maxlen,len(chars)))
for t,char in enumerate(sentence):
x[0, t, char_indices[char]] = 1
# 次の文字を予測
preds = model.predict(x, verbose =9)[0]
# 次の1文字のインデックス
next_index = sample(preds, diversity)
# 次の1文字
next_char = indices_char[next_index]
# 次の1文字を追加する
generated += next_char
# 2文字目からに、次の1文字を追加した40字(1文字ずらした40字)
sentence = sentence[1:] + next_char
# 次の1文字をコンソールに出力
sys.stdout.write(next_char)
sys.stdout.flush()
print()
model.save('souseki_model.h5')
file = open('sousekigentext.txt','w+',encoding='utf-8').write(generated)
今回は以上です。参考にしたサイトは以下です。
参考サイト:ディープラーニングで文章を自動生成したい!


[…] 夏目漱石『こころ』風の文章を自動生成 […]