
最近、Apache Sparkのスピードアップに取り組んでいます。その中でShuffle Partitionの設定値を最適にすることでShuffleプロセスのスピードアップができるのではないか?と思って少し勉強中です。
そこで、今回は、shuffle.partitionの最適な設定値ってどのくらいなの?という疑問について調べてみたことを簡単にまとめました。私自身、内容の理解が完全ではないので、個人的なメモの意味合いが強い記事です。正直、私自身理解していないので、この記事にはかなり間違いがあるかと思います。
 と〜げ
と〜げ
今後、少しずつ理解を深めていければと思います。今後も加筆修正をしていきます。もし、間違いを見つけたら、優しく教えていただけたら幸いです。
Shuffle Pratitionシャッフルパーティション
Spark データ処理の流れ
Sparkはデータを「パーティション」という単位で並列処理をします。流れは以下。
- データの読み出し
HDFS上のブロック単位のファイルを読み出し、各ブロックをパーティションとして扱います。
パーティション数 = HDFSから読み出したブロック数 - データを並列に変換
1パーティションを1タスクとして並列に変換処理されます。
パーティション数 = タスク数 - シャッフル処理
groupByやjoinなどの処理は、パーティション間のデータ交換が生じます。これがシャッフル処理です。このときのパーティション数がShuffle Partitionで、デフォルトで200に設定されています。 - データの書き込み
処理結果をパーティション単位で並列に書き込みます。
Shuffle Partitionのデフォルト値
Shuffle Partitionのデフォルト値は、以下コマンドで確認できて、デフォルト値は200に設定されています。
spark.sql.shuffle.partitions
しかし、私が観たDatabricksの動画(Youtube)によると、ほとんどケースにおいてデフォルト値200というのは適切ではないみたいです。動画のスピーカーもなぜデフォルトがこの値なのかわからないと言っています。

Shuffle Partitionの設定方法
ちなみに、Shuffle Partitionの設定方法は以下コマンドでできます。これで1000に設定できます。
sparkSession.conf.set("spark.sql.shuffle.partitions",1000)
最適なShuffle Partitionの設定値とは
では、最適なShuffle Partitionの設定値はどうやって求めればいいのか?私も全くわかりません。そして今もよくわかっていません。とりあえず、Databricksの動画(Youtube)の内容についてまとめてみます。
Shuffle Partitionについて、以下のような式が紹介されています。Target Sizeは、1つのPartitionのサイズのことで、100MB〜200MBに設定することが良しとされているようです。
spark.sql.shuffle.partitions= Shuffle Stage Input Size / Target Size(100MB~200MB)
ここで例を挙げましょう。
- Shuffle Stage Input = 210GB
- spark.sql.shuffle.partitions= 210GB/200MB = 1050
ただし、もしクラスターが2000のコア数を持つ場合は、2000に設定すべきです。パーティションはコア数よりも少なく設定すべきじゃないらしいです。私が思うに、1partitionを1コアが処理するため、最適でもパーティションはコア数以上に設定すべきということだと思います。
次に、Spark UIを絡めて、あるクラスターでのある処理について見ていきましょう。
- Cluster : 96 cores
- Stage19, 20, 21から成るJob
Stage19, 20それぞれのアウトプットがStage21のInputとなっています。これはDAGからもわかります。
※Stageはshuffleによって分けられる
Details for Stage 21に注目します。まず、一つのPartitonサイズ(Target Size)がどうなっているのかを見てみましょう。先ほど紹介したように100MB~200MBが良いとされています。
spark.sql.shuffle.partitions= Shuffle Stage Input Size / Target Size(100MB~200MB) から
Target Size = Shuffle Stage Input Size / spark.sql.shuffle.partitions と書けます。
ここで、Shuffle Stage Input Size ≒ 54GB です。Stage21のShuffle Read = 53.9GBであり、これは、Stage19,20のShuffle Writeの合計値(45.4GB + 8.8GB)でもあります。若干のずれは放っておきましょう。。。
そして、spark.sql.shuffle.partitions = 200 です。Stage21のTasks Succeeded Totalが200/200なっているのは、このデフォルト値が200だからです。つまり、Shuffle PartitionとTask数はイコールとなるようです。
よって、Target Size = 54GB / 200 = 270MB となります。100MB~200MBが良いので少し大きい値となっています。Shuffle Read Size のMediumも大体270MBとなっています。これは、各Task(各Partitionの)のShuffle Read Sizeの中央値を示しています。
また、この動画内ではSpillという問題についても触れています。
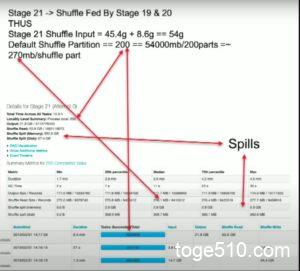
Shuffle Spill (Memory) = 557GBとなっています。Taskごとで見ると、約3GBのShuffle spill (Memory)が発生しています。Spillとは、『こぼれる』という意味です。Shuffle spill (Memory)はメモリーにに乗り切らなかったこぼれたデータサイズのことです。Spillが発生すると、処理が遅くなるのでSpillを発生するべきではありません。
かなりごちゃごちゃしてきましたが、結論を言うと、spark.sql.shuffle.partitions = 480とすることで、Shuffle Read Sizeを下げて、Spillの発生を抑えて、処理速度を速くすることができると動画で説明されています。
では、なぜ、480なのか?
Target sizeを100MBとすると、spark.sql.shuffle.partitions = 54GB / 100MB = 540 となります。なのに、なぜ480なのか?この理由はよくわかりませんでした。わかったら、後で追記します。
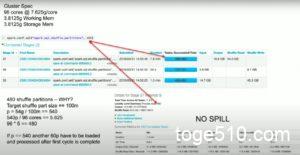
とにかく、480に設定することで、Target size = 54GB/480 = 112.5MBとなります。Shuffle Read Size のMediumをみても115.2MBとなっており、大体同じくらいの値です。
と、結局訳がわからなくなってしまいましたが、要はspark.sql.shuffle.partitionsをデフォルトの200から480に変更することで、処理速度が上がったということです。
と〜げ
かなり、なんとなくですが、最適なspark.sql.shuffle.partitionsをSpark UIの結果を見ながら設定することができそうです。本当にかなりなんとなくですが。。。

